Is logging necessary?
During development, logging is normally seen as an unnecessary burden, because you are working in a debugger. When the program crashes, your editor immediately pops up, highlighting the cause of the crash. When the program is behaving strangely, you can pause the program and inspect all relevant values.
Not so for software that's been sent to production, where there is no debugger. When the program crashes, all the user sees is a standard windows crash dialog and a sudden lack of application. When the program exhibits strange behaviour, the user can do nothing to find out why. Short of releasing all programs as source and requiring that all users run your software through a debugger, you need to know the state of the program prior to the crash.
This is the role of the logger - like ship captains of yore, it writes down every tedious little happening in a sequential list - a log. You can read the log afterwards and deduce a snapshot of the application state at any particular moment during its execution. When you get a report that the program has crashed or is doing things wrongly, you no longer have to desperately try to reproduce the problem yourself. Just ask for the log file, print it out, and sit down to deduce the error over a cup of tea like a ninja.
In any sufficiently interesting software, logging is crucial.
Is logging hard?
In principle, no. In practicle, yes. There are many pitfalls that can render a log file less than useful when disaster finally strikes.
The problems that most commonly haunt conventional log files are:
- Buffering. Usually just a big performance gain when writing to disk IO, buffering potentially means that the last hundred log entries have not yet been written to the log file when your program crashes. A log containing just some application startup info is about as useful as a paper cup in a storm.
- Multithreading. Multiprocessing your application is a good way to speed it up by several orders of magnitude. For logging, however, it means that two threads can try to log at the same time. A usual result of this is interleaved log entries, i.e. thread A logs "socket created" while thread B logs "shutting down database" at the same time, possibly resulting in the misleading log entries "shutting down socket" and "created database".
- File access rights. Access rights is serious business in Windows Vista and above. For logging, this means that if a user has decided to launch your application with "Run as administrator" the first time, the log file will be created with "Administrator" as owner. When running the application later as a normal user, he is now unable to append to the log file, and the program either crashes or doesn't log anything.
- Growing log file. After a while, your log file will grow to an improper size. It is foremost bad form to fill up your users' disks without their consent, but it is also difficult to read huge log files. If they are particularly large, they might even crash your Notepad when you open them.
But let us step back for a moment and look at the bigger puzzle. Do these problems have a common cause? Can we avoid these problems altogether?
Yes, the common cause is that you are operating with files. And yes, we can avoid these problems altogether with...
A Better way of Logging
To download the logger assembly, click here.
The solution is so obvious that I was half surprised no-one had thought of - or at least implemented - it before; log to the Windows Registry.
Let us look at how it affects our earlier problems:
- Buffering. Windows registry storage, and consequently disk IO buffering, is done on the OS level instead of application level. This means that no buffers are lost when your program crashes.
- Multithreading. The Windows registry access functions are already thread-safe, so you don't have to do anything.
- File access rights. No file means no file rights headaches! Nuff said.
- Growing log file. Since we no longer operate on a monolithic blob of bytes, but rather on discrete registry key values, we can remove entries willy-nilly. This means we can simply delete the oldest entries in O(1) time to keep the total log size within an approved threshold.
The entire logger source code looks like this:
// Logger.cs
using System.Collections.Generic;
using Microsoft.Win32;
namespace RegistryLogger {
public class Logger {
private RegistryKey logRoot;
private int headIdx;
private int tailIdx;
private int maxLogLength;
/// <summary>
/// Create logger object with Max Log Length of 10.
/// </summary>
/// <param name="appName">Name of your App.</param>
public Logger(string appName) : this(appName, 10) { }
/// <summary>
/// Creates key HKCU\SOFTWARE\LOGS\[appName].
/// Logger is now ready for use.
/// </summary>
/// <param name="appName">Name of your App.</param>
/// <param name="maxLogLength">Limit total log storage to this many
/// entries.</param>
public Logger(string appName, int maxLogLength) {
this.maxLogLength = maxLogLength;
string lrp = "SOFTWARE\\LOGS\\" + appName;
RegistryKeyPermissionCheck pc =
RegistryKeyPermissionCheck.ReadWriteSubTree;
logRoot = Registry.CurrentUser.OpenSubKey(lrp, pc);
if (logRoot == null) {
logRoot = Registry.CurrentUser.CreateSubKey(lrp, pc);
headIdx = tailIdx = 0;
logRoot.SetValue("headIdx", headIdx);
logRoot.SetValue("tailIdx", tailIdx);
} else {
headIdx = (int)logRoot.GetValue("headIdx");
tailIdx = (int)logRoot.GetValue("tailIdx");
}
}
/// <summary>
/// All currently stored log entries.
/// </summary>
public string[] Entries {
get {
List<string> area = new List<string>();
for (int i = tailIdx; i < headIdx; i++)
area.Add((string)logRoot.GetValue(i.ToString()));
return area.ToArray();
}
}
/// <summary>
/// Prepend a timestamp to the entry and log it as string value
/// HKCU\SOFTWARE\LOGS\[appName]\[idx]
/// Each new log entry gets an unique idx.
/// </summary>
/// <param name="entry">Entry to log.</param>
public void Log(string entry) {
string toLog = System.DateTime.Now.ToString() + ": " + entry;
logRoot.SetValue(headIdx++.ToString(), toLog);
logRoot.SetValue("headIdx", headIdx);
DeleteOldEntries();
}
private void DeleteOldEntries() {
while (headIdx - tailIdx > maxLogLength)
logRoot.DeleteValue(tailIdx++.ToString());
logRoot.SetValue("tailIdx", tailIdx);
}
}
}
Remember how I said the buffering, multithreading, access rights workarounds for log files were cumbersome? Look how elegant we can keep the code when those concerns are noncerns.
A simple test run
To download the logger source and the test application, click here.
To test this, I created a GUI interface in WPF to let you read and write log entries.
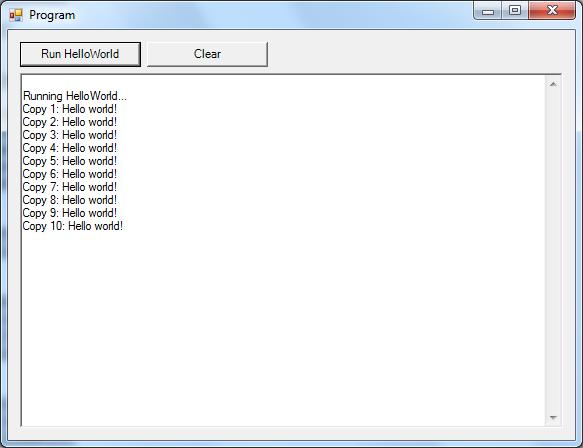
Let us enter a few sample entries and submit them to the logger:

Clicking the "Log Above Lines" button causes each line to be logged as a separate log entry. To see what we have logged, we can click "View Log":

Ok, looks good. But I bet you a can of tomatoes that I can guess what you are thinking right now. "How does this look in the registry?"
Let's have a look:

The entries are all there! We can also see the current logger state: The headIdx value says that the next entry to be logged will get idx 7, while the tailIdx value says that the oldest stored entry has idx 0. Since we can deduce every stored entry idx by starting from tailIdx and iterating up to headIdx, this is literally equivalent to a linked list. As anyone who has at least passed close by a computer science department knows, linked lists make for easy FIFO queues, and FIFO queues makes for easy constant-size buffers: If the size is too large, move the tail pointer and delete the previous tail element. Rinse, lather, repeat until size is within threshold.
For demonstration purposes, I've limited the logger to 10 entries. We now have 7 log entries, so let us see how it behaves when we add another 4:

Click "Log", which should take us to exactly 11 total entries, 1 above the threshold. Click "View":

As we can see, the first log entry "Application starting." is now deleted! Just to be sure, let us check the registry:

The entry with idx 0 is now gone, and the tailIdx is 1. Success!
In closing
Hopefully, you now know enough to implement proper logging in your applications. Whether you decide to use my logger code (free open source, as always) or roll your own registry logger, I will be very interested in hearing how it works out for you.
If you have any questions, don't hesitate to use the comments section.